How we run parallel merge queues on our own monorepo
In a monorepo, one merge queue makes everyone wait in a single line. Scopes let Mergify batch related pull requests, reuse CI, and run unrelated changes in parallel. Here's how we set it up on our own repo.
In a monorepo, a single merge queue makes everyone wait in one line. Change a line of docs and your pull request sits behind someone’s backend refactor. When the PR at the front of the queue fails its tests, the PRs behind it get pulled back and retested too. The bigger the repo, the more that one shared line hurts.
Scopes fix this. You tell the merge queue which parts of the codebase a pull request actually touches, and Mergify uses that to batch related changes together and run unrelated ones in parallel. We’ve been running it on our own monorepo for months. Here’s how it works and how we configured it.
If you’d rather watch, here’s the short version, recorded on our own repo:
Telling the queue what a PR touches
A scope is an area of your codebase: the frontend, the backend, the installer, a Docker image. The merge queue can’t guess these boundaries, so you define them.
The simplest way, and the one we use, is file patterns. You map each scope to the paths that belong to it:
merge_queue:
mode: parallel
max_parallel_checks: 5
scopes:
source:
files:
installer:
include:
- installer/**
dashboard:
include:
- dashboard/**
exclude:
- dashboard/README.md
- dashboard/src/@types/openapi/api-types.d.ts
engine:
include:
- engine/**
docker:
include:
- docker/**
- engine/pyproject.tomlA pull request that only changes files under dashboard/ gets the dashboard scope. One that touches both dashboard/ and engine/ gets both. The exclude list matters more than it looks: a docs-only edit or a generated type file shouldn’t drag the whole dashboard test suite into the batch, so we keep those paths out of the scope.
If your boundaries don’t map cleanly to directories, you don’t have to use file patterns. You can compute the scopes yourself with Bazel, Nx, Turborepo, or anything else, and upload them through the API or the CLI. Mergify treats the result the same way.
Batching pull requests that belong together
When several pull requests are ready for the next batch, Mergify compares their scopes and groups the ones that overlap the most. Related changes get tested together, so they share the same CI run instead of paying for it twice. Unrelated changes stay out of that batch, which means a failure in one of them can’t roll back work it has nothing to do with.
That second part is the one people underestimate. In a flat queue, an unrelated broken PR three slots ahead of you still costs you a re-test. Scope-aware batching keeps that blast radius small.
Running scopes in parallel
This is the part I’m most happy with. Batches that live in independent scopes test at the same time instead of waiting their turn.
Think of it as one lane per scope. Frontend pull requests test and merge in the dashboard lane while backend pull requests do the same in the engine lane. Neither lane blocks the other. With a flat queue you’d have a single line where a slow frontend build holds up a backend change that never went near the frontend.
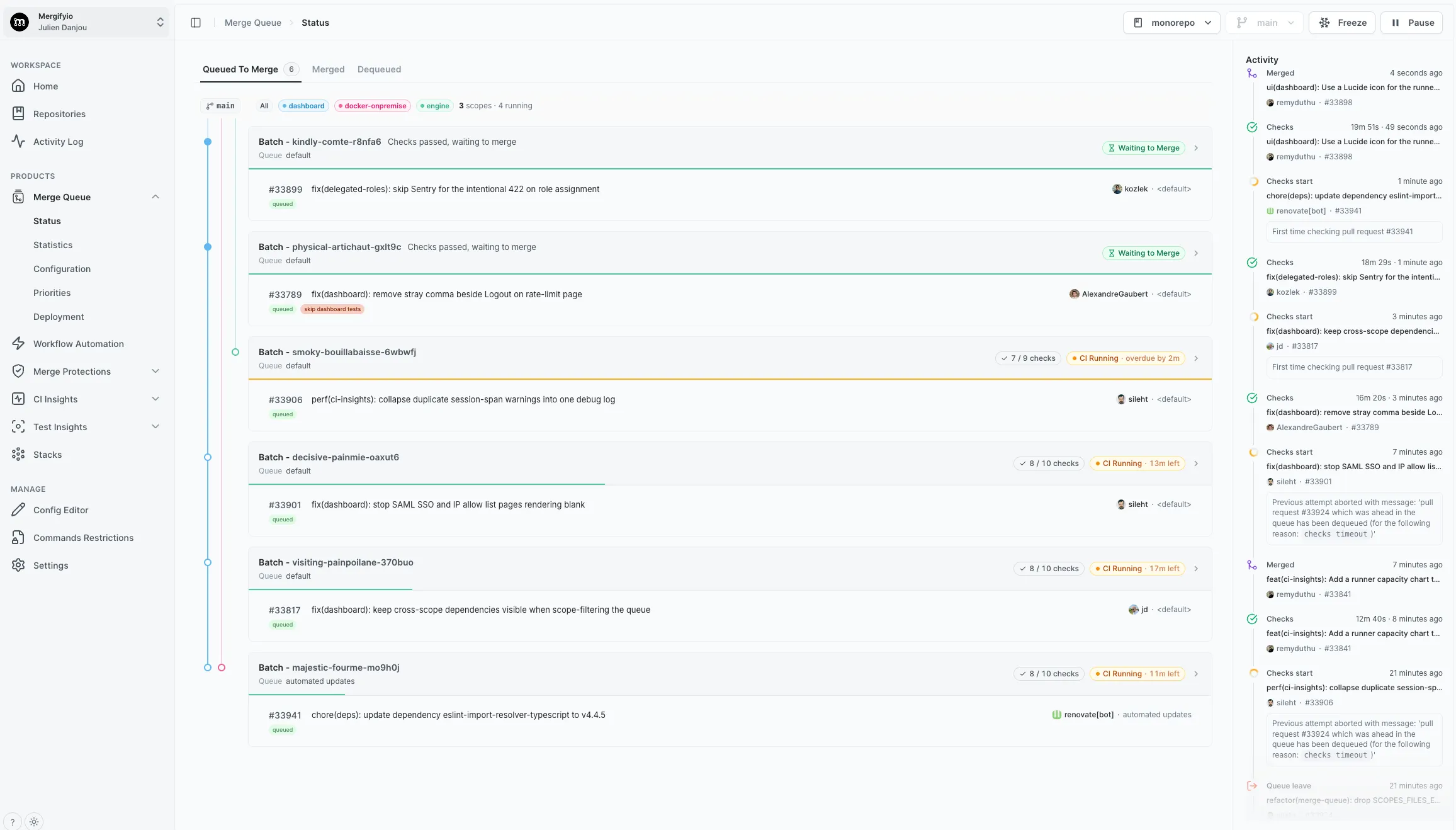
This is our actual queue. Three scopes, four batches in flight at once, each one testing on its own instead of waiting behind the others.
The failure behaviour is the real win. When a PR breaks in the dashboard lane, the engine lane keeps moving. The broken change is isolated to the scope it belongs to, and everything else keeps merging. For a team pushing dozens of PRs a day across a large repo, that’s the difference between a queue that flows and a queue that stalls every time someone’s test is flaky.
We run this every day
Our own repo is split into installer, dashboard, engine, and the Docker images. Every pull request we open is scoped automatically from the file patterns above, batched with the changes it actually relates to, and tested in parallel with the scopes it doesn’t. We didn’t build scopes as a demo feature and leave it on a shelf. It’s how we ship.
If you have a monorepo behind a merge queue, scopes are the setting that makes it scale. Start with file patterns for your top-level areas, add a few exclude rules for docs and generated files, and turn on parallel mode. The scopes documentation has the full reference.
