When a production deploy fails, our merge queue freezes itself

A failed production deploy used to be invisible to our merge queue, which kept merging onto a broken release. Here's the 66-line GitHub Actions job that now freezes the queue the moment any deploy scope fails, and why lifting it is a human's job.
A production migration failed. One minute later, our pipeline shipped the next deploy right on top of it, all green. Nothing in the pipeline thought that was a problem, so now a 66-line GitHub Actions job freezes our own merge queue the moment any production deployment fails.
The queue kept merging onto a broken deploy
At Mergify, every PR the merge queue lands on main deploys to production individually. The deploy workflow fans out into five scopes. The engine backend and the dashboard frontend are the big two; three smaller scopes ride along.
Five scopes means a deploy can half-succeed. When one scope fails, production becomes a version mix: the backend can be up to date while the frontend isn’t. Deploys are never atomic anyway, and users run stale browser bundles against fresh backends every day, so a brief one-scope skew is survivable. What a failed deploy changes is the direction. A merge only redeploys the scopes it touches, so the broken scope stays pinned while everything around it moves on: the skew widens with each merge instead of closing. The only sane move is to fix the deploy before anything else ships.
A merge queue doesn’t know that. Ours kept doing exactly what we configured it to do: merge the next PR and trigger the next deploy, pushing more changes onto a production we already knew was inconsistent. During one incident, an engine migration failed and the next deploy went out green one minute later. We found out from failure notifications piling up in the Slack channel that tracks deployments.
The deploy workflow now freezes the queue
The fix is an aggregate job at the end of the deploy workflow. It waits on all five deploy scopes and fires when any of them fails:
freeze-merge-queue:
# every deploy scope; the engine and dashboard jobs are shown, the three
# smaller ones are elided here for brevity
needs: [engine-deploy, dashboard-deploy]
if: ${{ github.ref == 'refs/heads/main' && !cancelled()
&& contains(needs.*.result, 'failure') }}When it fires, it calls the Mergify CLI to freeze the repository’s merge queue. A freeze blocks merging: PRs keep entering the queue and running their checks, but nothing lands until someone lifts it.
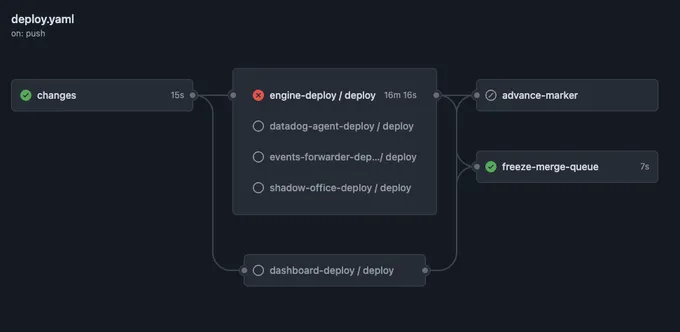
That’s the job doing its work on a real run: engine-deploy failed, so advance-marker was skipped and freeze-merge-queue fired instead.
reason_prefix="Production deployment failed"
run_url="$GITHUB_SERVER_URL/$GITHUB_REPOSITORY/actions/runs/$GITHUB_RUN_ID"
active=$(mergify freeze list --json \
| jq --arg p "$reason_prefix" \
'[.[] | select(.reason | startswith($p))] | length')
if [ "$active" -gt 0 ]; then
echo "An auto-created freeze is already active; keeping the original."
exit 0
fi
mergify freeze create \
--reason "$reason_prefix: $run_url" \
--timezone UTC \
--exclude "label=hotfix"The reason embeds the failing run URL, so anyone staring at a frozen queue is one click away from the why. Repeated failures don’t stack freezes either: deploy runs are serialized, and the job checks for an active auto-created freeze first, so the freeze keeps pointing at the first run that broke things.
PRs labeled hotfix are excluded from the freeze. The fix for the broken deploy still has a path through the queue, and our existing priority rule sends it to the front.
There’s a circularity here: the freeze call rides on Mergify’s production API, the very system whose deploy may have just failed. It’s smaller than it looks. A bad backend deploy rolls back automatically, so the API keeps serving the last good revision. The one thing we can’t roll back automatically is the database, which is exactly why every schema migration has to stay compatible with the version still running.
Lifting the freeze is a human’s job
The freeze has no end date and no automation removes it. For regular PRs there’s nothing to automate against: deploys only happen when a PR merges, and a frozen queue merges nothing. So short of re-running the failed workflow, no green deploy shows up to trigger an auto-unfreeze. The hotfix lane is the exception. We could lift the freeze automatically when a hotfix deploy goes green. We don’t want to: removing the freeze is a human saying “I understand what broke.” It takes two CLI commands (mergify freeze list, then mergify freeze delete <id>) or a couple of clicks in the dashboard.
The same reasoning covers auto-reverting. A revert PR is one hotfix label away from jumping the frozen queue if a human decides reverting is the right fix. The freeze buys time for that decision.
flowchart TD
A[PR merges to main] --> B[Deploy workflow runs five scopes]
B --> C{All scopes green?}
C -->|yes| D[Advance the production marker]
C -->|any failure| E{Auto-freeze already active?}
E -->|yes| F[Keep the original freeze]
E -->|no| G["Freeze the queue<br>reason: failing run URL<br>excluded: label=hotfix"]
G --> H[hotfix PR jumps the queue<br>and deploys the fix]
H --> I[Human lifts the freeze]
I --> A
The job is the mirror image of a gate we already had: every completed deploy run either advances the production marker (a git ref pointing at the last fully deployed commit) or, on any failure, freezes the queue. One small subtlety: the scope-detection job is deliberately not in needs, because if scope detection itself fails, nothing deploys, and there’s nothing to protect production from.
It has fired twice
The first time was a Cloudflare API outage. The dashboard couldn’t deploy because the upload API was down, while the backend scopes were fine. Without the freeze we would have kept shipping backend changes against a frontend stuck in the past.
The second time, a migration failed to apply on the test database, so the backend deploy stopped while the frontend had already shipped. A different failure from the one that started all this, and another version mix: the frontend was ahead, expecting a backend that wasn’t there yet. The freeze didn’t fix anything. It just made sure nobody piled more changes on top while we fixed the deploy.
No metrics here, and one honest limit: the freeze is reactive, so it can’t stop what merged while the failing run was still in flight. Deploy runs are serialized, so that’s one PR at most. Everything after it stops dead.
Freezing the queue blocks every engineer until a human lifts it. The team accepted that trade because in practice it doesn’t happen often. When it does, that’s the feature: a frozen queue is a good way to scream loudly that something’s not okay and needs to be fixed. A Slack notification can be ignored. A queue that won’t merge your PR cannot.
Why not just batch deploys?
There’s an obvious objection: batch your deploys and this whole class of problem shrinks. We deploy exactly once per merged PR on purpose, because some of our changes are stacked PRs that assume it. A two-step database migration (expand in PR one, contract in PR two) only works if PR one’s deploy has finished before PR two’s starts. “Exactly one deploy per PR” is the contract the rest of our tooling leans on. So when a deploy fails, the line stops instead, the same move as pulling a factory andon cord.
The easiest tool was the right one
I picked a Mergify freeze because it was the easiest mechanism available. We already sell the merge queue this job freezes, and the whole thing fits in 66 lines of YAML with no new service and no state to manage. Maybe it ends up deeper inside the Merge Queue product someday; we’ll see.
You don’t need Mergify for the idea. If your queue admits PRs based on a required status check, your deploy workflow can start failing that check; if it’s a branch ruleset, an API call can toggle it. Either way, deploy failure has to feed back into whatever admits merges.
If a failed deploy doesn’t stop your merge queue today, the queue is doing exactly what you configured. Sixty-six lines of YAML changed what ours was configured to do.
