Pattern 1
cargo test parallel threads racing on shared state
Symptom. A test that mutates a static `Mutex<HashMap>` passes alone and fails under `cargo test` with a panic about a value the failing test never inserted.
Root cause. cargo test runs tests on a thread pool inside a single process. Anything those threads share (a static cell, an environment variable read at startup, the working directory, the filesystem at a fixed path) becomes a race the moment two tests touch it. The borrow checker stops you from sharing &mut T across threads, but it cannot stop two tests from agreeing to share the same Mutex.
static REGISTRY: Mutex<HashMap<String, u32>> = Mutex::new(HashMap::new());
#[test]
fn registers_alice() {
REGISTRY.lock().unwrap().insert("alice".into(), 1);
let r = REGISTRY.lock().unwrap();
assert_eq!(r.len(), 1);
}
#[test]
fn registers_bob() {
REGISTRY.lock().unwrap().insert("bob".into(), 2);
let r = REGISTRY.lock().unwrap();
assert_eq!(r.len(), 1); // fails: 2 when both tests ran
}
Fix. Move shared state inside the test body so each test owns its own. When a test must mutate a true global (env vars, the working directory), serialize it with the serial_test crate so cargo skips parallel scheduling on those tests.
#[test]
fn registers_alice() {
let mut registry: HashMap<String, u32> = HashMap::new();
registry.insert("alice".into(), 1);
assert_eq!(registry.len(), 1);
}
// For env vars or other unavoidable globals:
#[test]
#[serial]
fn reads_required_env() { /* ... */ }
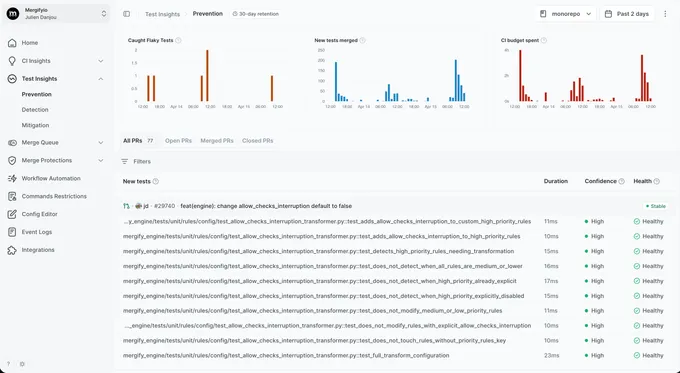
With Mergify. Test Insights catches the parallel-only signature: a test only fails when run alongside a sibling and passes alone. The dashboard tags it as parallelism-sensitive so you know to look for shared globals rather than a logic bug in the test itself.
Pattern 2
OnceCell and lazy_static initialization order
Symptom. A test that reads a `Lazy<Config>` passes when run alone and fails when run after another test that wrote to a config-loaded environment variable.
Root cause. OnceLock and once_cell::sync::Lazy initialize the first time the value is read, then cache forever. If your Lazy reads an environment variable at first access and a test mutated that variable beforehand, every later test in the process sees the mutated value. The cell never re-initializes.
static CONFIG: Lazy<Config> = Lazy::new(|| {
let url = std::env::var("API_URL").unwrap_or("https://api.test".into());
Config { api_url: url }
});
#[test]
fn config_uses_default_url() {
// Whichever test runs first wins; if 'config_uses_override_url' raced
// ahead and set API_URL, this assertion fails.
assert_eq!(CONFIG.api_url, "https://api.test");
}
#[test]
fn config_uses_override_url() {
std::env::set_var("API_URL", "https://api.override");
assert_eq!(CONFIG.api_url, "https://api.override");
}
Fix. Avoid Lazy for anything tests need to vary. Pass configuration through function arguments or build a fresh instance per test. When the cache is part of production code's contract, isolate the env-mutating tests with serial_test and reset the env in a teardown.
#[derive(Clone)]
struct Config { api_url: String }
impl Config {
fn from_env() -> Self {
Self {
api_url: std::env::var("API_URL").unwrap_or("https://api.test".into()),
}
}
}
#[test]
fn config_uses_default_url() {
assert_eq!(Config::from_env().api_url, "https://api.test");
}
With Mergify. Test Insights detects the cross-test signature: a test only fails after a specific sibling has run, and only on cold cargo runs (warm cache hides the issue locally). The dashboard surfaces the ordering so the cached-Lazy root cause is the obvious lead.
Pattern 3
Tokio runtime per-test races
Symptom. An async test that uses `tokio::spawn` passes alone and fails in the suite with a `dispatch task is gone` panic or a hung connection.
Root cause. #[tokio::test] creates a fresh Tokio runtime for each test by default. A test that spawns a long-running task and returns before the task finishes leaves an orphan task on a runtime that is being dropped. Inside the suite, the next test starts on a brand new runtime where the orphan's connections, channels, and timers no longer make sense.
#[tokio::test]
async fn schedules_a_refresh() {
tokio::spawn(async {
loop {
tokio::time::sleep(Duration::from_millis(10)).await;
refresh().await;
}
});
// returns immediately; the spawned task lingers on a dropped runtime
}
#[tokio::test]
async fn checks_state() {
// sometimes hangs because refresh() is still running on a dead runtime
let s = state().await;
assert_eq!(s.count, 0);
}
Fix. Hold a JoinHandle and either .await it before returning, or pair the spawn with a CancellationToken the test cancels in a guard. For tests that genuinely need a shared runtime, use Runtime directly and own its lifecycle explicitly.
#[tokio::test]
async fn schedules_a_refresh() {
let token = CancellationToken::new();
let child = token.child_token();
let handle = tokio::spawn(async move {
loop {
tokio::select! {
_ = child.cancelled() => break,
_ = tokio::time::sleep(Duration::from_millis(10)) => refresh().await,
}
}
});
// ... assertions ...
token.cancel();
handle.await.unwrap();
}
With Mergify. Test Insights surfaces the cross-test signature: an async test passes alone and hangs only when a specific sibling ran before it. The dashboard groups the failures by their predecessor so the leaking spawn is easy to find.
Pattern 4
Time-based assertions without a synthetic clock
Symptom. A test that waits 100ms and asserts a side effect happened passes locally and fails on the slower CI runner with a tick that arrived a millisecond late.
Root cause. tokio::time::sleep uses the runtime's wall clock by default. A test that sleeps 100ms races against scheduler jitter; locally the spare CPU finishes in 102ms, on CI the throttled runner finishes in 105ms and the assertion fires before the side effect lands. Without a virtual clock, every timing assertion is a race.
#[tokio::test]
async fn refresh_fires_every_100ms() {
let count = Arc::new(AtomicUsize::new(0));
let c = count.clone();
tokio::spawn(async move {
loop {
tokio::time::sleep(Duration::from_millis(100)).await;
c.fetch_add(1, Ordering::SeqCst);
}
});
tokio::time::sleep(Duration::from_millis(250)).await;
assert!(count.load(Ordering::SeqCst) >= 2); // sometimes 1 on CI
}
Fix. Use Tokio's tokio::time::pause to virtualize time. With the timer paused, sleep only advances when the runtime detects every task is parked. tokio::time::advance moves time deterministically, so 100ms is exact instead of approximate.
#[tokio::test(start_paused = true)]
async fn refresh_fires_every_100ms() {
let count = Arc::new(AtomicUsize::new(0));
let c = count.clone();
tokio::spawn(async move {
loop {
tokio::time::sleep(Duration::from_millis(100)).await;
c.fetch_add(1, Ordering::SeqCst);
}
});
tokio::time::advance(Duration::from_millis(250)).await;
assert_eq!(count.load(Ordering::SeqCst), 2);
}
With Mergify. Test Insights links timing failures to their CI runner type. When a test only fails on the slower runner pool and never on the laptop pool, the dashboard surfaces the resource sensitivity so the real-clock dependency is the obvious place to look.
Pattern 5
tempfile cleanup that depends on Drop ordering
Symptom. An integration test that creates a `tempfile::TempDir` passes when run alone and fails when run alongside a test in the same module with a `No such file or directory` error.
Root cause. TempDir deletes its directory when it is dropped. If two tests share a directory by giving it a fixed name (or by deriving the name from a shared static counter), the first test to drop wipes the directory the second is still using. The borrow checker has no opinion on filesystem aliasing.
static SHARED_DIR: Lazy<TempDir> = Lazy::new(|| TempDir::new().unwrap());
#[test]
fn writes_a_file() {
let path = SHARED_DIR.path().join("data.txt");
std::fs::write(&path, b"hi").unwrap();
assert!(path.exists());
}
#[test]
fn reads_a_file() {
let path = SHARED_DIR.path().join("data.txt");
let s = std::fs::read_to_string(&path).unwrap();
// sometimes fails: writes_a_file's dir was Dropped on a parallel thread
assert_eq!(s, "hi");
}
Fix. Give every test its own TempDir created inside the test body. The dir is dropped when the test returns, with no aliasing across tests.
#[test]
fn writes_a_file() {
let dir = TempDir::new().unwrap();
let path = dir.path().join("data.txt");
std::fs::write(&path, b"hi").unwrap();
assert_eq!(std::fs::read_to_string(&path).unwrap(), "hi");
}
With Mergify. Test Insights tags failures whose only signature is a missing-file error correlated with a sibling test that touches the same path. The dashboard surfaces the aliased-tempdir pattern so the fix lands once instead of test-by-test.
Pattern 6
Async test attribute interactions
Symptom. A test annotated `#[tokio::test(flavor = "multi_thread")]` passes locally and deadlocks on CI when combined with a `#[serial]` attribute or a custom test harness.
Root cause. Rust's procedural macro attributes apply outside-in. #[serial] from serial_test, #[tokio::test], and #[traced_test] each rewrite the function body. Stacking them in the wrong order can produce a function that takes a lock before the runtime starts, blocks forever waiting for itself, or runs the body twice. The error is rarely the test's logic; it is the macro stack.
#[serial] // outer
#[tokio::test] // inner
async fn pings_the_server() {
// serial_test 0.x wraps in a sync mutex; the future starts before
// the lock releases. With the multi-thread flavor, a worker that needs
// the same lock to make progress deadlocks on CI's slower scheduler.
let r = client.ping().await;
assert!(r.is_ok());
}
Fix. Read the documentation for each macro and follow the recommended ordering. For serial_test with tokio, use the async-aware variant (#[serial(async)]) so locking happens inside the runtime, not around it.
#[tokio::test]
#[serial(async)] // works inside the runtime
async fn pings_the_server() {
let r = client.ping().await;
assert!(r.is_ok());
}
With Mergify. Test Insights groups attribute-related deadlocks by their failure timeout signature. A test that times out at exactly the runner's wall-clock limit and never produces output is the fingerprint, and the dashboard surfaces the affected files together.
Pattern 7
Environment variable mutation across tests
Symptom. A test that sets `LANG=C` for ASCII-only output passes alone and breaks an unrelated test that asserts on a localized error message.
Root cause. std::env::set_var mutates the process-wide environment. Tests run in the same process, so a set in test A is visible to test B running in parallel, even if test B never touched the variable. The Rust 2024 edition is making set_var unsafe for exactly this reason.
#[test]
fn formats_in_ascii() {
std::env::set_var("LANG", "C");
assert_eq!(format_message(), "error");
}
#[test]
fn formats_localized() {
// sometimes the previous test set LANG=C and won the race
std::env::set_var("LANG", "fr_FR.UTF-8");
assert_eq!(format_message(), "erreur");
}
Fix. Pass configuration through function arguments instead of environment variables wherever possible. When a test must mutate the env, run it serially with #[serial] and restore the original value in a guard so other tests are not affected.
fn format_message(lang: &str) -> &'static str {
match lang { "C" => "error", _ => "erreur" }
}
#[test]
fn formats_in_ascii() { assert_eq!(format_message("C"), "error"); }
#[test]
fn formats_localized() { assert_eq!(format_message("fr_FR.UTF-8"), "erreur"); }
With Mergify. Test Insights groups env-mutation failures by their assertion text. When several seemingly unrelated tests start failing with localization or path errors after a sibling sets an env var, the dashboard surfaces the upstream culprit.
Pattern 8
`cargo test` shell-level retries hiding real bugs
Symptom. Your CI is green. A user hits a race in production that your suite was supposed to catch.
Root cause. Cargo itself does not have a retry flag, but it is common to wrap cargo test in a CI script that retries the entire suite on failure to "smooth out flakes". A real race that loses on attempt 1 and wins on attempt 2 gets reported as green. The bug is still there. The pipeline has decided not to look at it.
# CI script (please don't)
cargo test --workspace || cargo test --workspace || cargo test --workspace
Fix. Do not retry at the shell level. When a test is genuinely flaky, fix it. When the fix takes longer than a session, quarantine it instead. That keeps the signal visible without blocking the merge queue.
With Mergify. Test Insights reruns at the CI level with attempt-level result tracking. You see that a test passed on attempt 2 of 3, which is exactly the information shell-level retries throw away. Quarantine kicks in once the pattern is clear.