The Magic (and Mayhem) Behind Our Config Deprecation Transformers

We built a "self-healing" system that fixes deprecated configs by opening PRs automatically. It worked like magic, until it didn't. Here's what we learned about the thin line between elegant automation and uncontrollable complexity.
Every now and then, you build something that feels a little too magical, the kind of system that does its job beautifully until the day you have to debug it.
Our configuration deprecation transformer framework is exactly that kind of system.
It started with a simple problem: we deprecate things a lot.
The Problem: Invisible Deprecations
As our product evolved, we often needed to rename or remove attributes in our configuration schema. At the time, our deprecation flow was… polite but useless.
When we deprecated a field, the only signal users got was a warning in a GitHub check-run. No one reads check-runs. (Honestly, neither do I unless something’s red.)

Users continued to push configurations with deprecated fields. Our team would reach out manually, explain the change, and sometimes even submit PRs to fix it for them. It was tedious, slow, and invisible.
We needed a better way. Something that made deprecations impossible to ignore and ideally, self-healing.
The Idea: Self-Updating Configs
What if, instead of posting a warning, we could open a pull request in the user’s repository that automatically (or at least tries its best to) fix their config?
That’s what our “configuration deprecation transformer” system does.
When it receives an event for a repository, it scans it, tries to detect deprecated attributes or logic, and, if needed, creates or updates a PR with the corrected configuration.
Users don’t just get notified; they get a ready-to-merge solution (most of the time).
How It Works (at a High Level)
The system has two main parts: detection and transformation.
1. Detection
When receiving an event for a repository, we check its configuration file to look for potential deprecations. To avoid overloading our CPU and memory, it uses a cache to minimize this check frequency: if the SHA of the config file hasn’t changed, we skip it.
We check whether any attributes or logic patterns are marked as deprecated. If we find something, the repository gets pushed into a queue for transformation.
The “deprecated” flags come directly from our Pydantic models — attributes carry a deprecated metadata field that signals when they’re obsolete.
class MyConfig(BaseModel):
old_field: str = Field(..., deprecated="Use `new_field` instead")
new_field: strThis means deprecations are defined where they belong: next to the schema itself.
2. Transformation
A second worker consumes that queue. For each repository, it:
- Loads the current config.
- Applies the relevant transformers (small pieces of code that rewrite the config).
- Opens or updates a pull request with the fixed version.
A simplified transformer might look like this:
class DeprecatedAttribute:
path_to_field: list[str]
field_name: str
deprecation_message: str
deadline: datetime.datetime
class DeprecatedAttributeTransformer(BaseTransformer):
deprecated: typing.ClassVar[list[DeprecatedAttribute]]
def transform(self, config):
config["new_field"] = config.pop("old_field")
return configTransformers can also handle higher-level “logic” deprecation: not just single attributes. For example, if an old combination of fields implies a deprecated behavior, a logic transformer can detect and rewrite it.
If a PR already exists, the system checks whether it needs to be updated (for new deprecations) or closed (if the user has already manually fixed the issue).
That feedback loop makes the process resilient and low-maintenance.
The Magic: Automatic Detection and Import
The real “magic” lies in how transformers get discovered and applied.
We actually support two interfaces for transformers:
- Attribute transformers (linked to a deprecated field): each deprecated attribute of our configuration has the “deprecated” attribute set to
Truewhen it is being deprecated. Then the system dynamically matches those attributes to transformers we’ve written in a specific package, which it automatically imports and registers. - Logic transformers (linked to more abstract conditions): for “logic” transformer we just have to extend some transformer interface, and implement the method that checks if the configuration file contains the logic it wants to detect and deprecate.
Those “interfaces” are what make it really easy to make a transformer and test it.
When we need to deprecate something, we write a new transformer, write some tests, and then ship it. The transformation pull requests begin to be created shortly after it is released (depending on the activity on each repository).
It’s magic and works, almost, perfectly without maintenance.
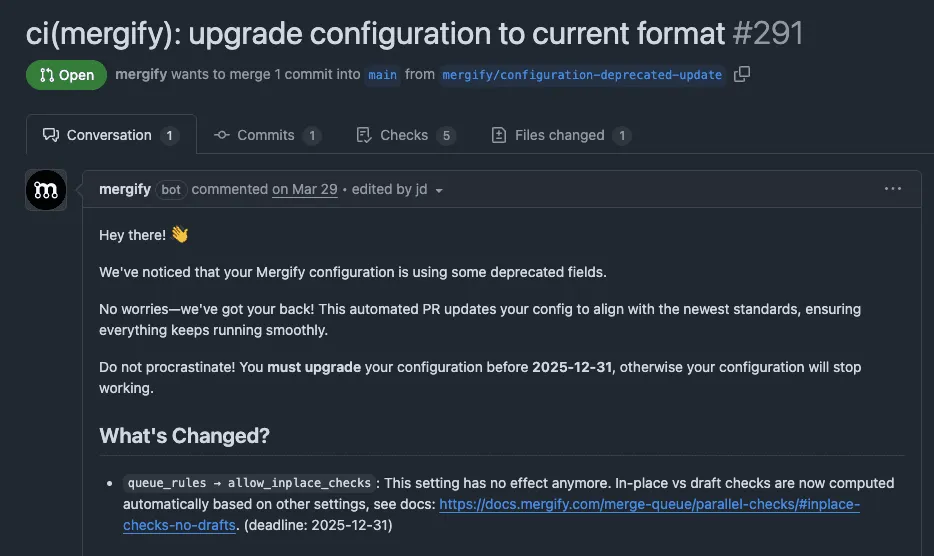
The Mayhem: Debugging the Undebuggable
When something goes wrong, following the code path feels like spelunking through a cave system with two maps drawn by different people.
There are two separate packages involved (detection and transformation), several classes with almost identical names, and very few logs because we didn’t want to spam the logs with thousands of daily events.
So when the system misbehaves (say, a transformer doesn’t run, or runs twice), figuring out why is sometimes a challenge. The dynamic imports obscure the call chain, and even with comments, the intent isn’t always obvious.
It’s one of those rare systems that’s so elegant in concept and so opaque in practice that even the person who wrote it (me) has to pause and trace carefully to remember what’s happening.
Recently, we wrote a transformer for an attribute that was being deprecated, which, as it turns out, didn’t have a test to ensure that the attribute was indeed deprecated. So we released the transformer and eagerly waited for the deadline of the deprecation, to remove all this useless deprecated code, only to realize a few weeks (a deprecation usually last ~ 3 months) before the deprecation that the transformation pull requests were not opened as expected for all the impacted users of this deprecation.
Debugging seemed like it would be easy at first, since there were quite a lot of comments to explain the behavior of this system, and I was the one who wrote it, but even with this “advantage,” I took a few hours before realizing that the magic didn’t work correctly. The transformer was supposed to deprecate a top-level section of our config, which couldn’t have a “deprecated” attribute in our models, hence why it wasn’t detected properly.
Fortunately for us, the “logic” transformers could quickly solve that issue by writing a small heuristic to check if this top-level section was present in the configuration file.
The Outcome
Despite the pain points, the payoff has been huge.
- Users immediately see deprecation PRs in their repositories, rather than obscure check-run warnings.
- Most of those PRs can be merged as-is, meaning users can fix issues without lifting a finger.
- We save hours of manual communication every time we evolve our schema.
It’s one of those tools that quietly does the right thing most of the time, and when it does, it feels almost alive.
Reflection
If I could rebuild it, I’d keep the same concept but invest more in transparency on how and why every element of the system interacts, and with each other. The magic isn’t the problem: the invisibility is.
When you build a system that changes code automatically, make sure you can explain exactly why it did what it did.
Magic is great, until the magician forgets how to undo the trick. 🪄


