Shadow Shipping: How We Double-Executed Code to Ship Safely
How do you ship risky code without crossing your fingers? In this post, we explain how he ran old and new logic in parallel (“shadow shipping”) to validate behavior in production before rollout. Learn how this simple pattern turned feature-flag anxiety into data-driven confidence.
Changing production logic is scarier than most engineers admit. A single conditional can quietly alter user behavior, and by the time you notice, it’s already affecting customers.
Recently, I had to rewrite a small but delicate part of our system: the logic that decides whether a pull request should be computed in-place or handled through a temporary draft pull request. It may seem minor, but this rule significantly influences how users interact with our automation. A regression here could go unnoticed in tests but confuse real users instantly.
So instead of crossing my fingers and flipping the feature flag, I tried something different.
I ran both versions of the code, old and new, in production, at the same time.
The Problem: A Tiny Change with Big Blast Radius
The decision logic in question looked innocent:
“Should this pull request be computed directly, or should it go through a draft first?”
That boolean controls a whole branch of workflow behavior.
It affects timing, visibility, and how automation interacts with user repositories.
The issue wasn’t that the new logic was complicated. It was that it changed assumptions baked into existing user habits. And there was no easy way to know how many users relied on the old behavior.
I could test the new code in isolation, sure — but synthetic tests don’t mirror real-world repository data or workflows. What I needed wasn’t more testing.
What I needed was evidence: how the new logic behaved under real traffic, with real users, before anyone felt the effect.
The Approach: Shadow Shipping
The idea originated from deployment patterns such as shadow traffic in backend systems.
Instead of replacing the old behavior outright, you run both versions in parallel and observe how they differ.
Here’s how I implemented it:
- The request still went through the normal path.
- Inside the handler, both the old and new logic were executed synchronously.
- If the two results differed, the system emitted a structured log with details (PR ID, user, old result, new result).
- The feature flag still determined which output was used in production.
Here’s the simplified version of the code:
old_result = old_decision_logic(pr)
new_result = new_decision_logic(pr)
if old_result != new_result:
log.warning(
"shadow_diff_detected",
pr_id=pr.id,
user=pr.author,
old=old_result,
new=new_result,
)
# Actual behavior still gated by the flag
if feature_flag_enabled("new_decision_logic"):
apply(new_result)
else:
apply(old_result)That’s it.
The same requests, the same users, but two pieces of logic racing behind the scenes, with only one result actually applied.
By logging differences, I effectively built a real-time audit of potential regressions without impacting any live behavior.
Observing the Differences: Datadog as a Diff Dashboard
All those structured logs flowed into Datadog.
From there, I built a timeseries dashboard showing whenever the old and new logic disagreed.
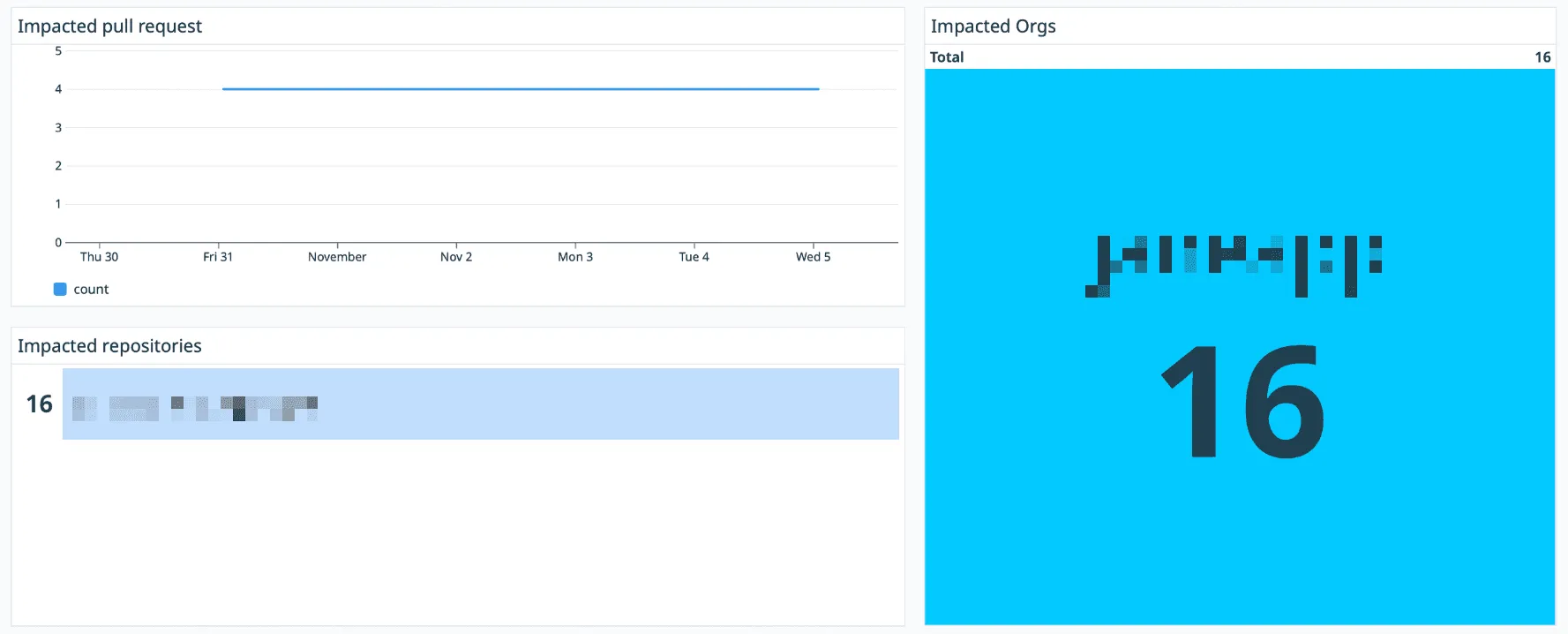
Each log entry represented a “diff” between versions:
- Which pull request was affected
- Which user triggered it
- What the old vs. new outcomes were
Visualizing that in Datadog turned out to be the key. I didn’t just get numbers; I could see patterns (or the lack of them).
A normal rollout dashboard shows metrics like latency or error rate. This one showed behavioral drift: the percentage of production requests that would behave differently under the new logic.
If that number spiked, I’d know instantly that the new logic had a wider impact than expected. If it stayed flat, I could ship confidently.
The Results: No Alarms, No Surprises
For the first few days, I kept the feature flag off, letting both versions run silently in parallel. The Datadog graph barely moved.
No divergence across thousands of requests: except for one.
That single impacted user? The person who originally requested the change. It was the perfect validation loop: the new behavior did exactly what it was supposed to do, and nobody else noticed.
When I finally toggled the feature flag, the rollout was anticlimactic in the best way possible. No regressions, no customer pings, no late-night incident threads. Just quiet confidence backed by real data.
Why It Worked
This pattern worked not because of fancy tooling, but because it respected three simple principles:
- **Production traffic is the best test data: **no synthetic load can mimic the quirks of real repositories, configs, or user habits.
- **Comparison beats assumption: **instead of speculating what might break, you let reality tell you.
- **Feature flags aren’t validation tools: **they control exposure but don’t tell you whether your logic actually works the same.
The double-run pattern fills that gap.
Was it expensive? Slightly. Running both code paths doubled CPU work for that specific function. But in exchange, I bought certainty.
The extra compute lasted a week. A rollback would have cost more (in time, stress, and reputation) than the additional runtime ever could.
Lessons Learned
A few takeaways became evident after this experiment:
**1. Shadow execution is a low-friction safety net: **you don’t need complex infrastructure to do it. For deterministic code, you can literally run both paths and compare. The overhead is minimal, and the confidence gain is huge.
**2. Observability is more potent than testing: **tests are snapshots; observability is a continuous video feed. By streaming differences into Datadog, I was effectively unit-testing production.
**3. Controlled rollout ≠ safe rollout: **a feature flag isolates exposure, but it doesn’t ensure parity. The double-run ensured logical equivalence before anyone was affected.
**4. Validation should happen where reality happens: **the best place to find subtle regressions isn’t staging: it’s production, under real load, where humans and automation interact in ways you’d never think to mock.
The Broader Lesson: Ship With Evidence, Not Hope
Shadow shipping isn’t just for massive infrastructure teams or ML inference pipelines. You can apply it anywhere deterministic logic matters: pricing calculations, feature gating, permissions, business rules It’s one of those patterns that quietly raises the quality bar.
You don’t even need to keep it permanent; just use it when you’re touching critical logic that affects user-visible behavior. Think of it like an A/B test for correctness instead of performance.
The goal isn’t to pick the faster or fancier version: it’s to make sure your “B” behaves exactly like “A” before you flip the switch.
Closing Reflection
In hindsight, I realized something simple: the anxiety of shipping complex logic isn’t really about the code: it’s about uncertainty.
Shadow shipping removes that uncertainty.
It’s a way of asking: “What would happen if we deployed this right now?”
And then answering it, safely, without actually doing it.
The next time you’re about to merge a change that feels risky, one that touches business rules, permissions, or workflows, try shadowing the logic instead of praying over the deploy button.
Because sometimes, the best way to test new behavior is to let it compete with the old one in the wild.
“Confidence isn’t about knowing nothing will break. It’s about having proof when it doesn’t.”


