Bun shipped 1M lines in nine days. The PR is the bottleneck now.

Bun's Rust rewrite landed as one PR with 6,755 commits and over a million lines. Claude wrote most of it. Nine days end to end. Here is what the four merge operations look like at that scale, and what a stack would have changed.
PR #30412 landed on Bun’s main branch on May 14, 2026: 1,009,257 lines added, 4,024 deleted, 2,188 files changed, 6,755 commits merged from a branch named claude/phase-a-port. Jarred Sumner floated the rewrite publicly nine days earlier. Claude wrote most of it. (Disclosure: Bun is now an Anthropic portfolio company.)
Dynamic workflows and adversarial code review was part of what made it possible to rewrite Bun in Rust in 6 days. Claude writes an orchestration script on the fly, then spins up a large fleet of coordinated subagents in parallel to take on your most complex tasks.
— Jarred Sumner (@jarredsumner) May 14, 2026
That’s the artifact. It passes the test suite, fixes a handful of memory leaks, and ships a smaller binary. Real engineering.
It’s also a load test of the pull request as a primitive. The PR was designed around the amount of code a human can write and read in one sitting. Bun #30412 is roughly five thousand of those, fused into one. GitHub literally had to display a banner warning that the diff viewer’s own features (Find on Page, Select All) may not work because the PR is too big. Whatever you think about the rewrite, the PR didn’t survive contact with that scale. Below: what each of the four merge-time operations actually looks like at this size, and what the same diff would have looked like as a stack.
Review
The math is funny.
1,009,257 lines. Assume you read one line per second. Not “understand”, not “review”, just eye → next line, the speed of a skim. That’s the upper bound for a human eyeball. At one line per second:
1,009,257 lines ÷ 60 = 16,820 minutes
16,820 ÷ 60 = 280 hours
280 ÷ 24 = 11.7 daysEleven and a half days. Continuous. No sleep, no coffee, no bathroom break. To skim, not to review.
Now a number that resembles actual code review. A focused reviewer on unfamiliar code does well to clear 200 lines per hour, which is roughly where industry numbers land. At 200 LOC/hour:
1,009,257 ÷ 200 = 5,046 hours
5,046 ÷ 8 = 631 working daysTwo and a half years of full-time review for one person. The PR was open for six days.
So in practice, line-by-line review of #30412 didn’t happen. It couldn’t. Reviewers trusted the test suite and Jarred, then clicked approve. That’s pragmatic. It’s also a real change in what “merged” means: code on main that nobody read.
This isn’t a critique of Bun’s process. No process reviews one million lines of Rust in nine days. The PR primitive ran out of headroom, and GitHub’s own warning banner on the diff page is the tooling admitting the same.
Bisect
Inside the PR branch, the 6,755 commits are preserved and remain technically bisectable. On main, the rewrite landed as one squash commit (23427db). When a regression shows up in production three weeks from now and somebody runs git bisect good main~50 bad HEAD, the search halts at “the Rust rewrite did it” with no further resolution.
That answer isn’t actionable. The next move is git log, git blame, and an evening of reading Rust you didn’t write. Post-merge bisect is the workhorse debugging tool for production regressions, and it just lost five thousand degrees of resolution.
You can still bisect the original branch, but only if you check it out and rebuild from each candidate commit. That’s roughly four orders of magnitude slower than bisecting on main, and the answer doesn’t help you patch main anyway.
Revert
git revert 23427db reverts all 1,009,257 lines. There’s no “revert just the bundler” or “revert just the HTTP server”. The blast radius of any rollback is the whole runtime. If any one subsystem turns out to be broken in a way you can’t patch quickly, your only escape hatch takes the whole rewrite with it.
In practice nobody runs that revert. The cost is too high. The runtime stays in Rust, the bug gets patched in Rust, and the rollback option is dead on arrival. That’s fine until the day it isn’t.
Rebase against main
For the six days the PR was open against main, every change on the Zig side had to be replayed on the Rust side. 6,755 commits in flight against an actively moving target. There are two ways this resolves:
- The author rebases continuously. The conflict matrix scales with the rate of main changes multiplied by 6,755 commits, and only the author can keep that state in their head.
- Main is effectively frozen for the rewrite window. Other contributors stall or queue behind the rewrite.
Either way, the PR scales sub-linearly with team size. Two people on a 1M-line PR are slower than one. Three are slower than two. That’s the opposite of what you want from a code review primitive.
The stack was already there
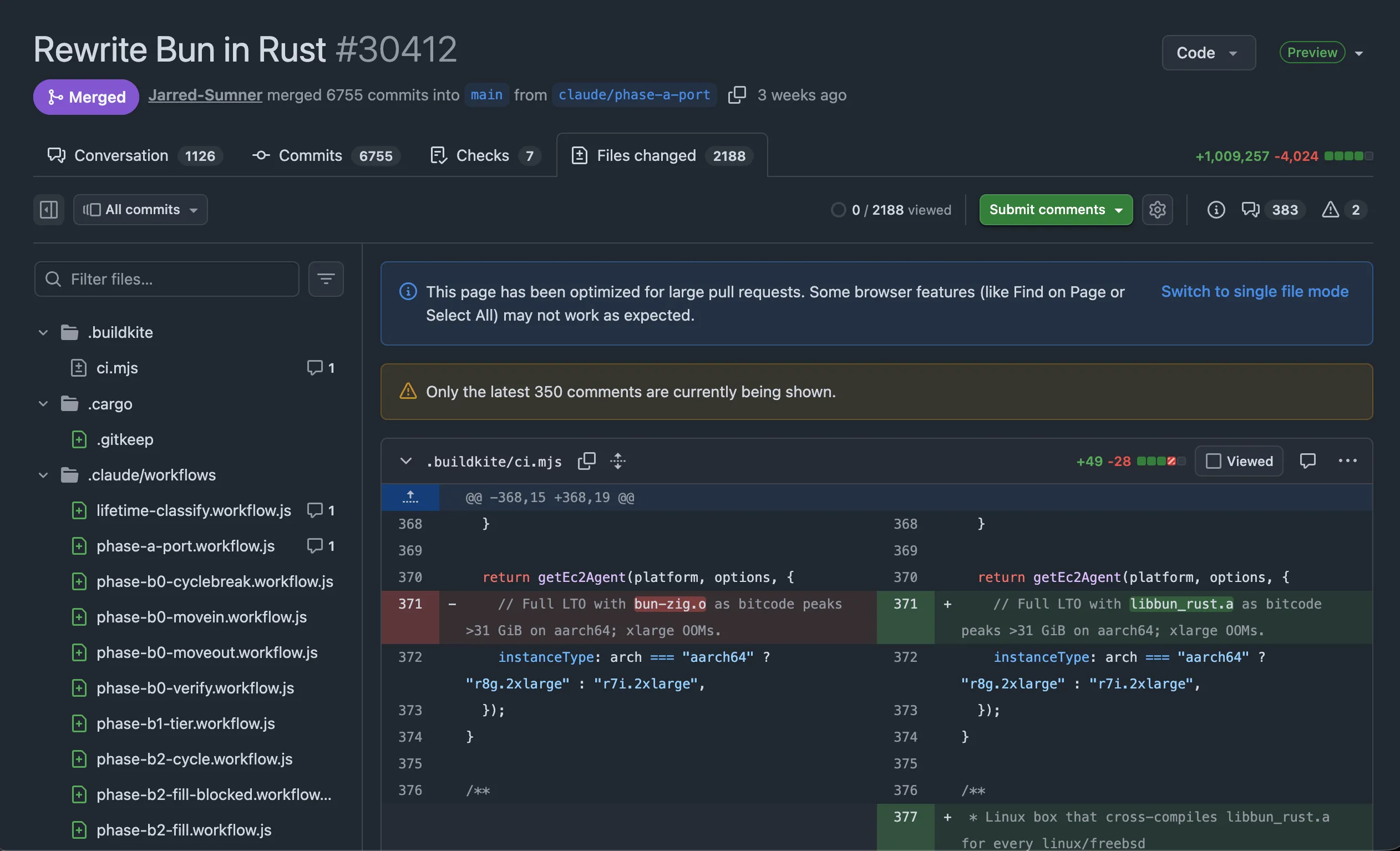
Look at the file tree on the left of the screenshot. Under .claude/workflows/ there are 52 workflow files. They group by phase letter:
phase-a : 1 file (initial port)
phase-b0 : 4 files (cyclebreak, movein, moveout, verify)
phase-b1 : 1 file (jit/interp tiering)
phase-b2 : 7 files (cycle, fill, fill-blocked, fix-bugs, keystone,
ungate-tier, verify)
phase-c : 1 file (panic-swarm)
phase-d : 9 files (bundler shards, todo sweep, unsafe audit, …)
phase-e : 5 files (proper-port, mass-ungate, scopeguard-sweep, …)
phase-f : 4 files (accessor-sweep, probe-swarm, test-swarm, …)
phase-g : 4 files (mega-swarm, test-swarm, test-swarm-v3,
test-swarm-isolated)
phase-h : 14 files (windows-bughunt × 2, windows-errors, libuv-audit,
idioms-audit, diff-review, dedup, …)
plus : lifetime-classify, porting-md-zigleakageThis is the workflow orchestration the team built to drive Claude. The rewrite isn’t one undifferentiated mass of code. It’s fifty-two named jobs, each producing a slice of the port: the initial Zig→Rust mechanical pass (phase A), then breaking cycles and moving code around so it compiles (phase B0), then the tiering pass for the JIT (phase B1), then the loop of fill/verify/fix-bugs until the runtime works (phase B2), then a panic swarm when things crash (phase C), then bundler sharding and audits (phase D), then test bringup (phase E), then test sweeps (phase F and G), then a long tail of Windows fixes and idiom sweeps (phase H).
Not all of this was planned. Phase A was the plan: do the mechanical Zig→Rust port. Everything after that accumulated as Claude hit problems and the team named the responses. phase-c-panic-swarm is what you write when things crash. phase-g-test-swarm-v3 exists because v1 and v2 didn’t work. phase-h-windows-bughunt-wt is a Wednesday afternoon. The workflows are what nine days of “drive Claude until the runtime works” actually looks like.
But each accumulation is still a named, scoped unit of work. That’s the part that matters. Whether the workflow was on the plan from day one or got created in panic on day six, it is a delineated job with a name and a diff. The branch name itself is claude/phase-a-port: even the team’s branch naming committed to the decomposition.
Then they recomposed it back into one PR for the human side.
That’s the part to undo. Each named workflow is already a stack slice. In a stacked world, phase-g-test-swarm-v3 is a new PR replacing the v2 PR, not a hidden commit inside a 6,755-commit megamerge. The retries, the panic swarm, the Windows sweep, all the things that look messy and embarrassing in retrospect, are exactly the kind of work that benefits from being shipped as small, individually-merging PRs instead of buried inside one diff. Emergent decomposition is still decomposition.
graph TD
A["phase A — port"] --> B["phase B0 — cyclebreak / move / verify"]
B --> C["phase B1 — tier"]
C --> D["phase B2 — fill / fix / keystone"]
D --> E["phase C — panic-swarm"]
E --> F["phase D — bundler / audits"]
F --> G["phase E — proper-port / tests"]
G --> H["phase F+G — test-swarms"]
H --> I["phase H — windows / libuv / idioms"]
I --> J["main"]
Each layer of that stack is independently:
- Reviewable by the engineer who owns that phase. The Windows-fix reviewer doesn’t need to read the initial port.
- Bisectable at phase granularity post-merge.
git bisectconverges on “phase D bundler-shard broke X”, not on “the rewrite”. - Revertible at phase granularity. If phase B1 tier turns out wrong, you pull phase B1 and leave the rest.
- Mergeable as it lands, not as a single nine-day all-or-nothing event. Phase A in main on day two, not day nine.
You could also slice by subsystem (HTTP server, bundler, JSC glue, fs, sqlite, ffi, child_process) instead of by phase. Either decomposition is in the source already.
The total work is the same. The integration cost isn’t.
None of which is to say stacks are magic. Phase A is still big: the initial mechanical port is the largest single phase, and “PR per phase” doesn’t mean “every PR is 200 lines”. Stacks shrink the unit of review by 10x or 20x, not by 1000x. The rest is a social problem (who owns what subsystem) and a CI problem (re-running tests on stacked changes when something upstream changes). Both are tractable, neither is automatic.
The other limit is producer/integrator coupling. If a reviewer asks for changes on phase A while Claude has already produced phase B on top, you rebase the downstream stack and re-run CI. Stacking tools handle that mechanically. The cost is real, but it’s bounded; one unreviewable PR isn’t.
The thing that actually changed
AI moved the bottleneck.
Before AI, megamerges were rare because writing 1M lines was hard. The PR was a fine primitive for the unit of work a human could produce. Reviewing what one person could write in a week was tractable.
After AI, writing 1M lines is a nine-day project for one person plus a model. The constraint flipped. The slow step is integration, not production. The PR primitive is sized for the producer, not the integrator, and the producer just got 1,000 times faster.
PR #30412 is the first canonical artifact of this. There will be more. As more teams point Claude at “rewrite this in Rust” or “port this codebase to TypeScript”, the artifact you get back is a 6,755-commit diff. The PR will accept it. Review won’t.
Stacks are the obvious response: keep the producer running at AI pace, keep the integration unit human-sized. Run the rewrite as the same 52-workflow decomposition the team already used to drive the AI, but ship it that way too.
What we’d do differently
If the Bun team had used Mergify Stacks, the rewrite branch would still be one local branch named claude/phase-a-port. Same workflows, same Claude orchestration, same nine days from public floating to merge. What changes is the merge.
Instead of one git push -u origin claude/phase-a-port followed by “Open pull request”, the team commits one workflow per commit and runs mergify stack push:
mergify stack new claude/phase-a-port
# One commit per workflow (52 total — phase-A through phase-H,
# plus the lifetime-classify and porting-md jobs). Showing the
# load-bearing port phases here for brevity.
git commit -m "phase-a-port: initial Zig→Rust mechanical port"
git commit -m "phase-b0-cyclebreak: untangle circular deps"
git commit -m "phase-b0-movein: relocate runtime/JSC glue"
git commit -m "phase-b0-moveout: split bundler off main runtime"
git commit -m "phase-b0-verify: assert phase B0 invariants"
git commit -m "phase-b1-tier: jit/interp tiering"
# … phase-b2-*, phase-c-panic-swarm, phase-d-*, phase-e-*,
# phase-f-*, phase-g-*, phase-h-* …
mergify stack pushFifty-two PRs land on GitHub instead of one. Each has the diff for exactly one workflow. The owner of the JSC runtime gets phase-b0-movein; the test-infra owner gets phase-f-test-swarm; the Windows owner gets phase-h-windows-bughunt; nobody is on the hook for a million lines.
Each PR also runs CI on its own. If phase-h-windows-bughunt fails on Windows, it fails alone, it doesn’t block phase-a-port from landing, and the failure points at the workflow that caused it instead of “something in the rewrite”. Per-PR CI is the difference between “the test suite is red, somewhere in 1M lines” and “phase-d-bundler-shard broke this one bundler test”.
What this looks like on GitHub:
graph TD
M[("main")]
A["PR #1 phase-a-port<br/>CI ✓ • approved • merging"]
B["PR #2 phase-b0-cyclebreak<br/>CI ✓ • approved • waiting on #1"]
C["PR #3 phase-b0-movein<br/>CI ✓ • in review"]
D["PR #4 phase-b0-moveout<br/>CI ✓ • in review"]
E["PR #5 phase-b0-verify<br/>CI ⏳ • running"]
F["… 46 more PRs<br/>each with own CI, own reviewer"]
Z["PR #52 phase-h-windows-singlefix<br/>CI ⏸ • Claude still writing"]
A --> M
B --> A
C --> B
D --> C
E --> D
F --> E
Z --> F
Compare to the alternative, which is what actually shipped:
graph TD
M2[("main")]
Big["PR #30412 — Rewrite Bun in Rust<br/>+1,009,257 / -4,024 • 2,188 files • 6,755 commits<br/>1 CI run for all of it<br/>6 days open, all-or-nothing"]
Big --> M2
Same nine days of work. One of these you can ship piecewise, review piecewise, bisect piecewise, and revert piecewise. The other you can’t.
When phase-a-port is approved, the Merge Queue tests it against main, lands it, and re-targets the next PR in the stack. Phase A is in main on day two, not day nine. By the time phase-h-windows-singlefix is up for review, phase A has been running in production for a week.
If phase-b1-tier breaks something, git bisect on main returns phase-b1-tier, not “the rewrite”. git revert phase-b1-tier pulls the tiering and leaves the port. Phase D reviewers read phase A as already-merged context instead of as 500k lines of unreviewed Rust sitting under their PR.
The producer still runs at AI pace while the reviewer still gets to be a human, and bisect and revert keep working. The PR primitive scales again because the unit of merge stays human-sized.
We build Mergify Stacks for this, but the argument stands without the tool. Graphite, Sapling, and ghstack all solve the same shape of problem. The primitive is the point. PR #30412 is the moment that became obvious.


